카테고리 없음
[S2-Week1]Multiple Regression
b___gly
2022. 4. 27. 17:30
Warm up
- R square(결정계수) :
- 0~1 사이의 값을 가지며, 회귀선의 설명력을 표현.
- 독립변수가 종속변수를 얼만큼 설명해주는지를 의미.
- 독립변수의 수가 증가하면 이 계수는 증가함.(큰 수의 법칙)
- 편차가 커지면 이 계수는 작아짐.
- 단지 회귀선의 설명력을 나타내는 것. 실제로는 큰 수가 나오기 어려움.
- 원자료나 scatter plot을 보면서 이상치를 제거해야함.
- 절대적인 기준은 없지만 2~30%면 괜찮은 듯.

- R square와 Standard Error of the Estimate의 차이 : (출처) https://www.youtube.com/watch?v=r-txC-dpI-E
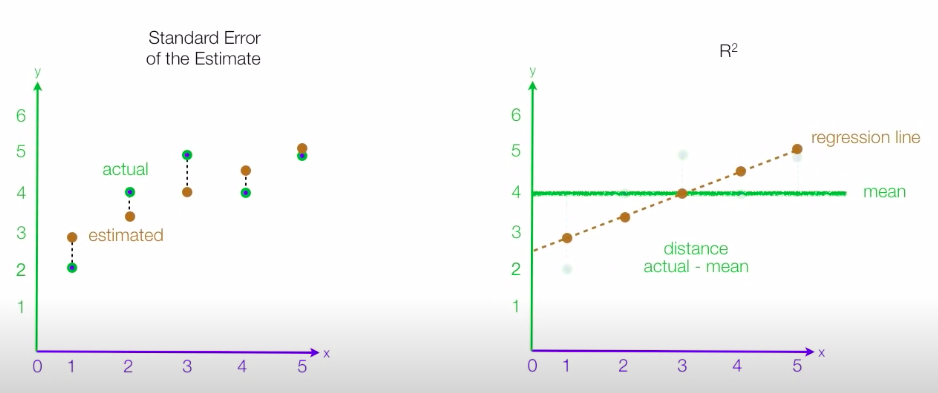
- 데이터 전부를 모델에 돌려보는 게 아니고, train data와 test data로 나눠서 train data로 모델 학습 시키고 test data로 확인.
- Straight line은 bias가 크나, variance(모델값과 test data사이의 거리)가 작음.
- Squiggly line은 bias가 작고, variance가 큼. 즉, 모델이 주어진 train data에 너무 overfitting(과적합)된다.
Session
- train data와 test data는 보통 무작위이긴 하나, 시계열 데이터 같은 경우는 test data를 더 미래의 것으로.
#직접 나눠주기
train = df.sample(frac=0.75)
test = df.drop(train.index)
len(train), len(test)
#sklearn 이용해서 나눠주기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)- 기본적인 model 설정 순서
#기준모델 설정(여기서는 회귀)
#target 설정
target = '궁금한 값(예측하고 싶은 값)'
y_train = train[target]
y_test = test[target]
predict = y_train.mean()
#MSA 계산
from sklearn.metrics import mean_absolute_error
y_pred = [predict] * len(y_train)
mae = mean_absolute_error(y_train, y_pred)#sklearn 썼을 때
#model 만들어주고
from sklearn.linear_model import LinearRegression
model = LinearRegression()
#feature 만들어주고 모델에 적용
features = ['설명해줄 변수']
X_train = train[features]
X_test = test[features]
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
#MAE 계산
y_pred = model.absolute_error(y_train, y_pred)
#test data 적용
y_pred = model.predict(X_test)
y_pred = model.absolute_error(y_test, y_pred)- 위의 것은 단순선형회귀모델, 다중선형회귀모델은 그냥 feature에 추가해주면 됨.
- 다중선형회귀모델은 plotly 라이브러리를 사용하면 시각화가 쉬움.
import numpy as np
import plotly.express as px
import plotly.graph_objs as go
import itertools
surface_3d(
df : 데이터프레임
f1 : 특성 1 열 이름
f2 : 특성 2 열 이름
target : 타겟 열 이름
length : 각 특성의 관측치 갯수
)- 회귀계수는 똑같이 구함 : model.intercept_, model.coef_
- 모델에 x값 넣어서 y값 구하고 싶으면 : model.predict([[궁금한 x1, 궁금한 x2]])
- 회귀모델을 평가하는 지표들 중에서 MSE를 가장 많이 사용하나, 제곱을 하기 때문에 단위 스케일에 영향을 받고, 이상치가 있는 경우 숫자가 확 튐.
# 회귀방정식 평가지표
mse = mean_squared_error(y, y_pred)
mae = mean_absolute_error(y, y_pred)
rmse = mse ** 0.5
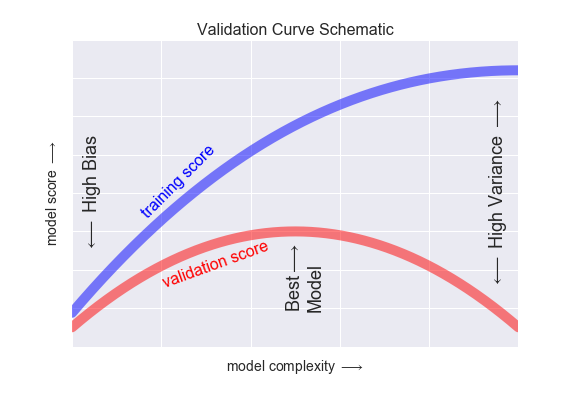
r2 = r2_score(y, y_pred)- train data와 test data에서 좋은 성능을 내는 것이 일반화가 잘 된 모델.
- overfitting : train data에서는 좋은 성능, test data에서는 나쁜 성능. 분산이 높음.
- underfitting : train data에서도 나쁜 성능, test data에서도 나쁜 성능. 편향이 높음.
- 분산(Variance)과 편향(Bias)는 trade-off관계
- 선형모델 예측은 편향이 높음 + 분산이 낮음 = 과소적합(underfitting)
- 곡선모델 예측은 편향은 낮음 + 분산이 높음 = 과적합(overfitting)
Quiz Coding
- 문자열 데이터는 정수형 데이터로 바꿔줘야 하는데, 아직 난 toInt 함수를 씀....
- train data로 모델 핏 시켜주고, y_pred는 X_test로 구하고, mae = mean_absolute_error(y_test, y_pred)로 해준다.
소감
잼따!!! 어려운 게 크게 없어서 좀 나음....ㅎ